Excel爬虫
Excel爬虫
使用Excel爬虫仅仅可以实现简单的数据爬取,主要是分为两类:一是网页页面存在有表格形式的数据;二是网页页面存在json形式数据。往往前者比较容易爬取,后者会比较困难,因为涉及到一些网页开发工具,相对而言使用excel爬取网页json数据不如python便捷,所以一般可以通过excel爬取网页的表格类型数据。
1. PowerQuery编辑器使用
需求:爬取淘宝天猫热销总榜销量,并使用PQ编辑数据
url:https://tophub.today/n/yjvQDpjobg
- Excel数据—新建查询—从其他源—自网站—输入上面的url—得到响应数据—将数据转换到PQ编辑器中
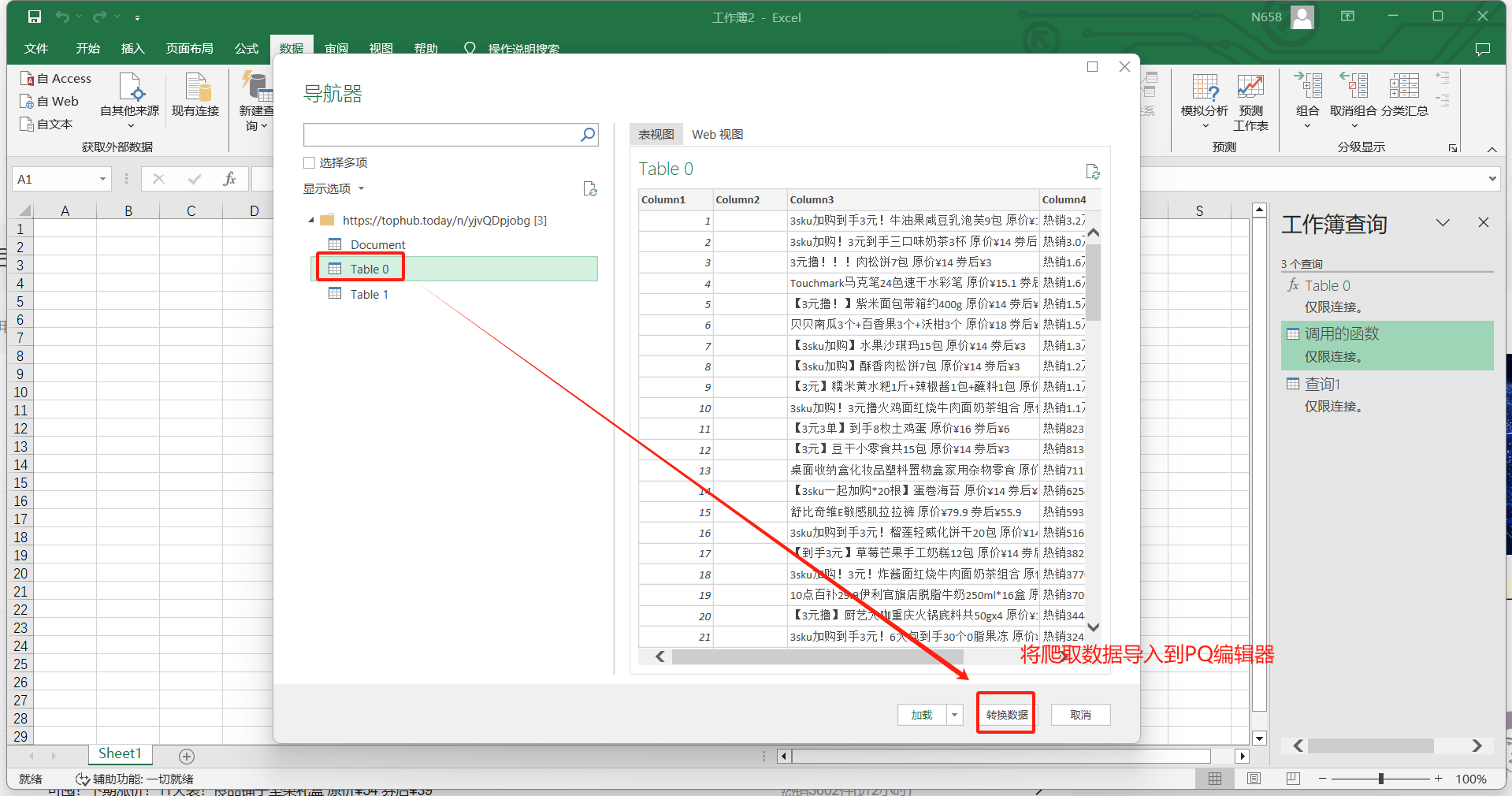
- 第二列是爬取页面的数据,由于该爬取仅针对于表格文本,所以无法爬取图片。将第三行的文本信息提取得到商品原价和券后价:划分列—按分隔符—选择或输入分隔符为空格
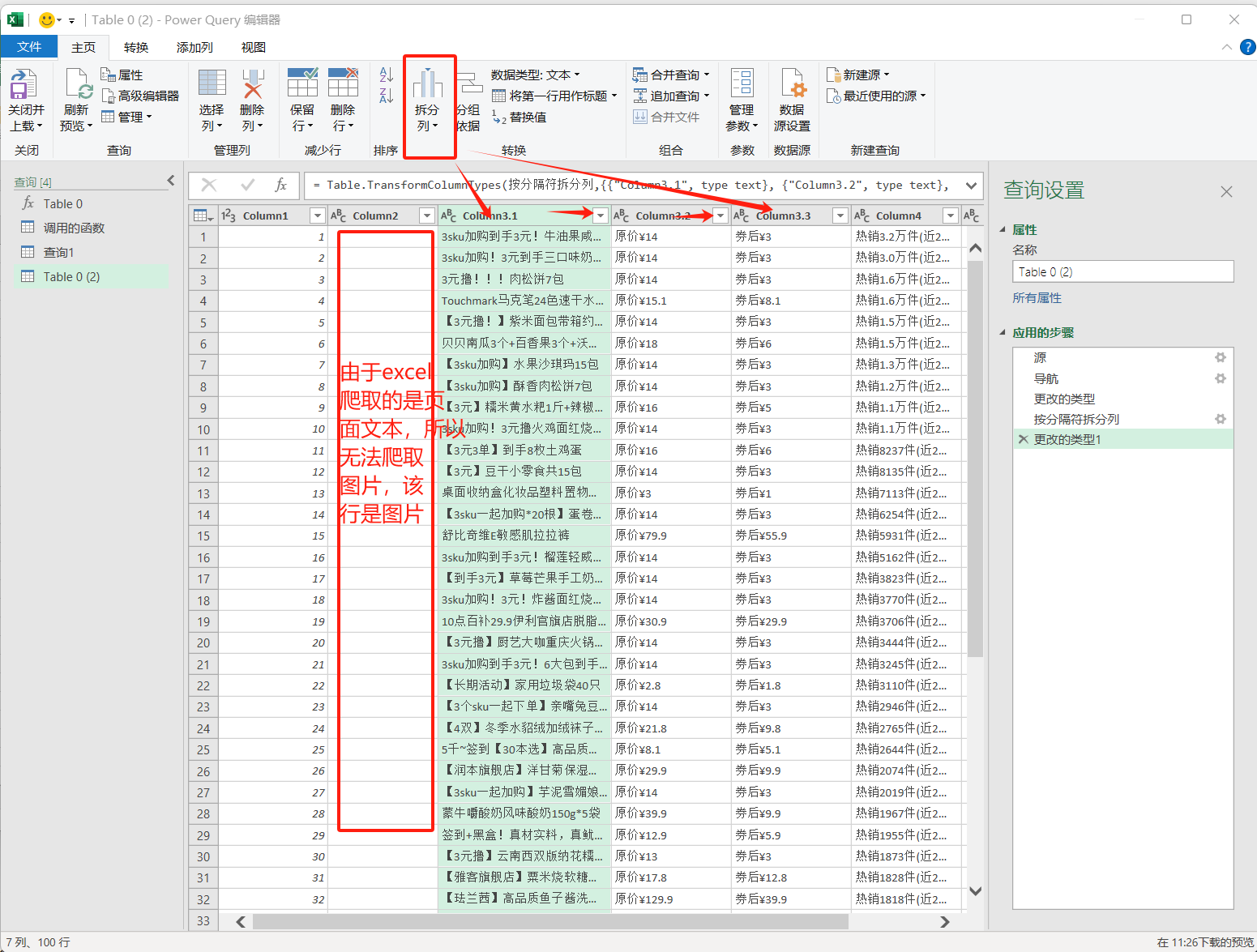
- 去除原价¥和券后¥标识,并得到数值型数据的价格类型:添加列——提取——分隔符之后的文本——选择“券后¥”、“原价¥”——转换——数据类型——选择为小数
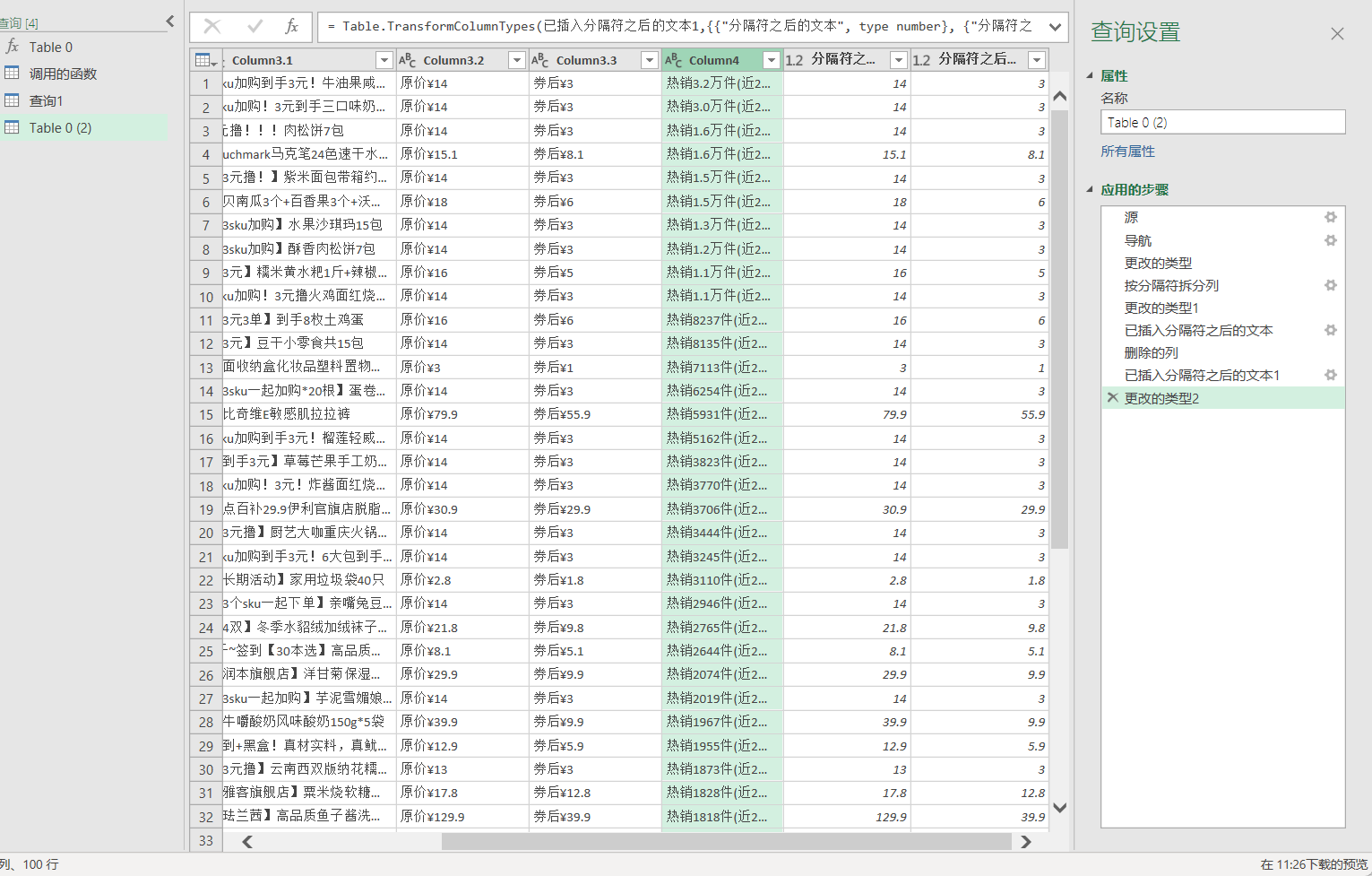
- 将第四列的热销数据提取出销量件数:添加列——提取——分隔符之间的文本——开始为热销,结束为件
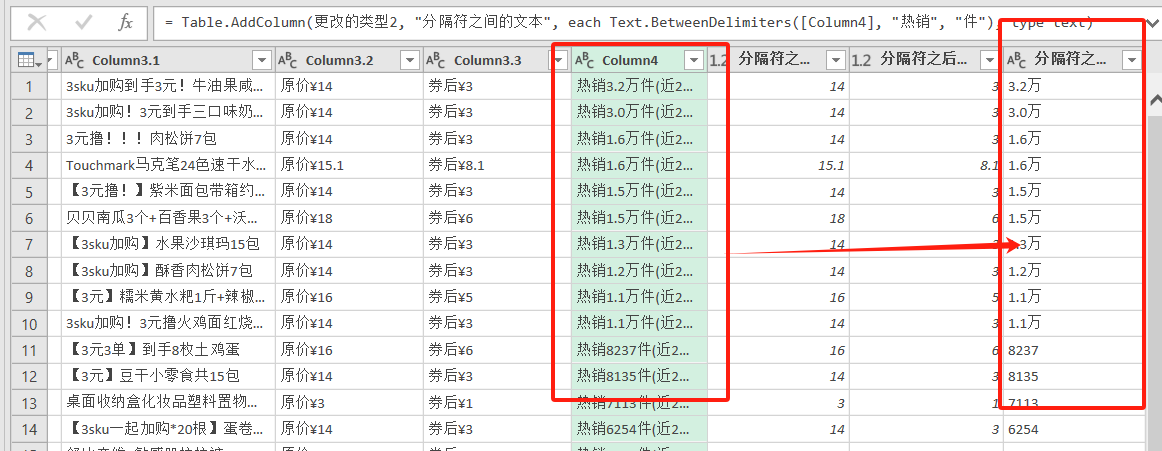
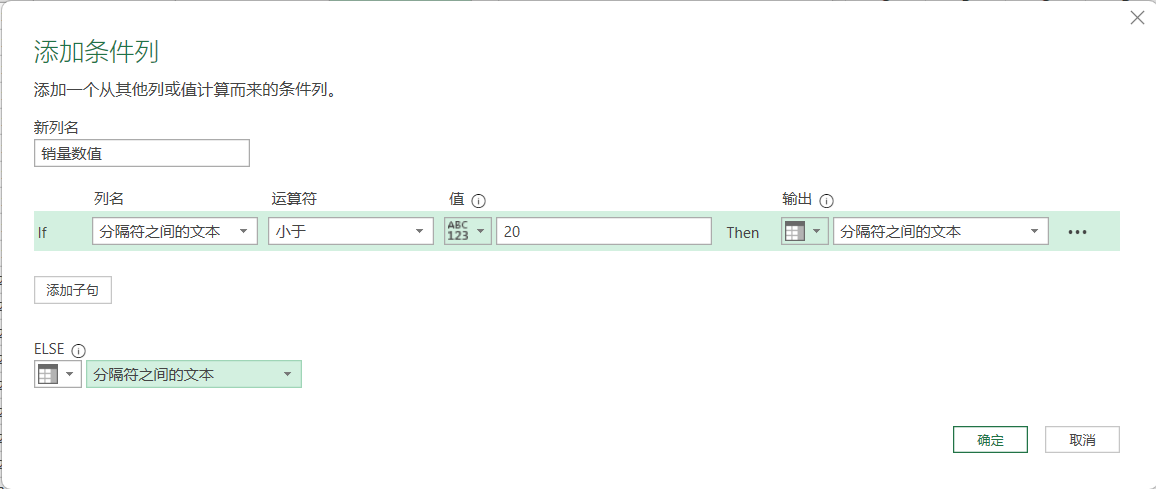
将分隔后得到的热销数据处理,将前面几个数据的单位万去掉,然后乘以10000,小于一万的不需要调整:转换——替换值——输入万,替换“ ”——转换为数值数据——添加列——条件列
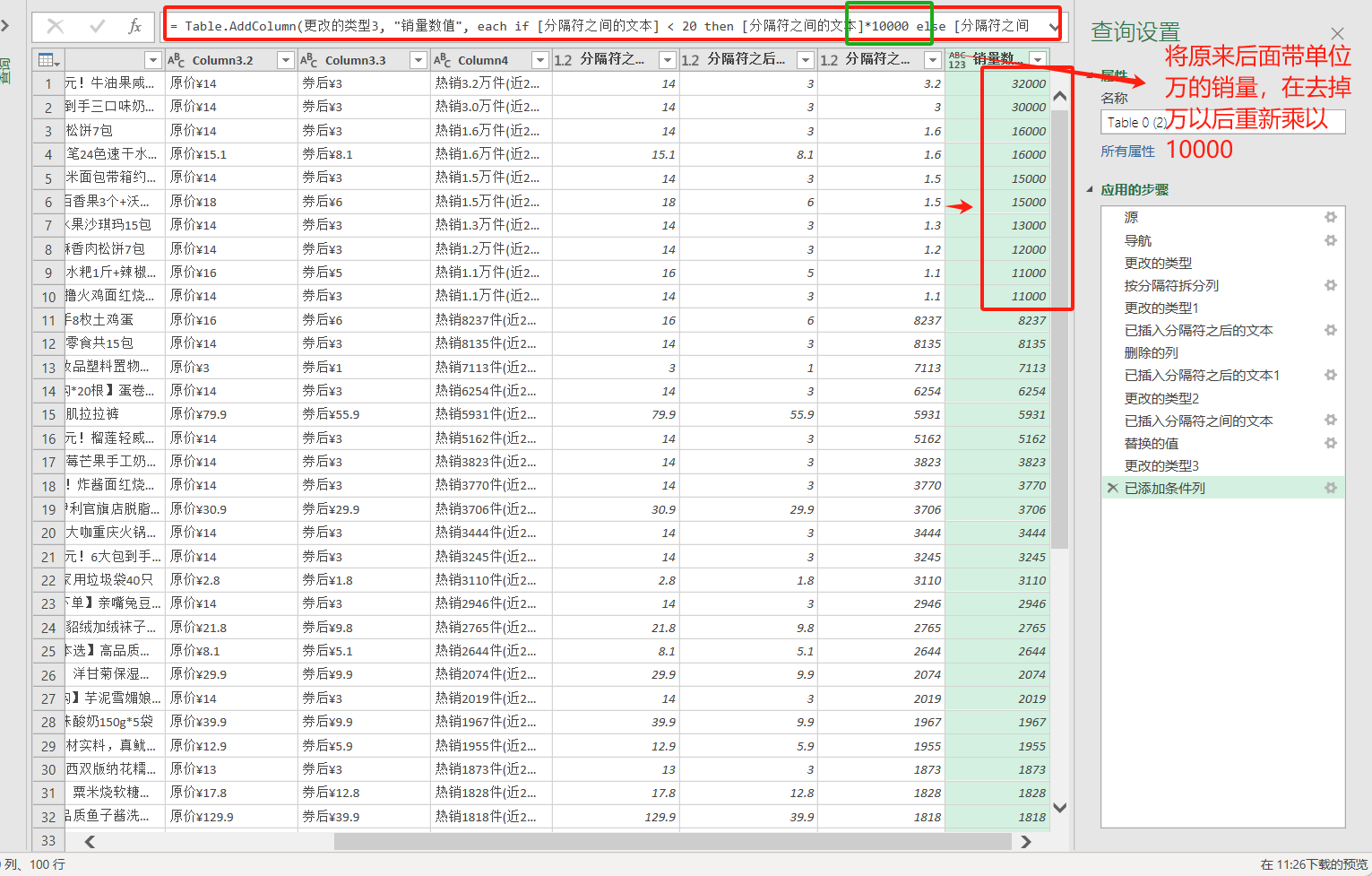
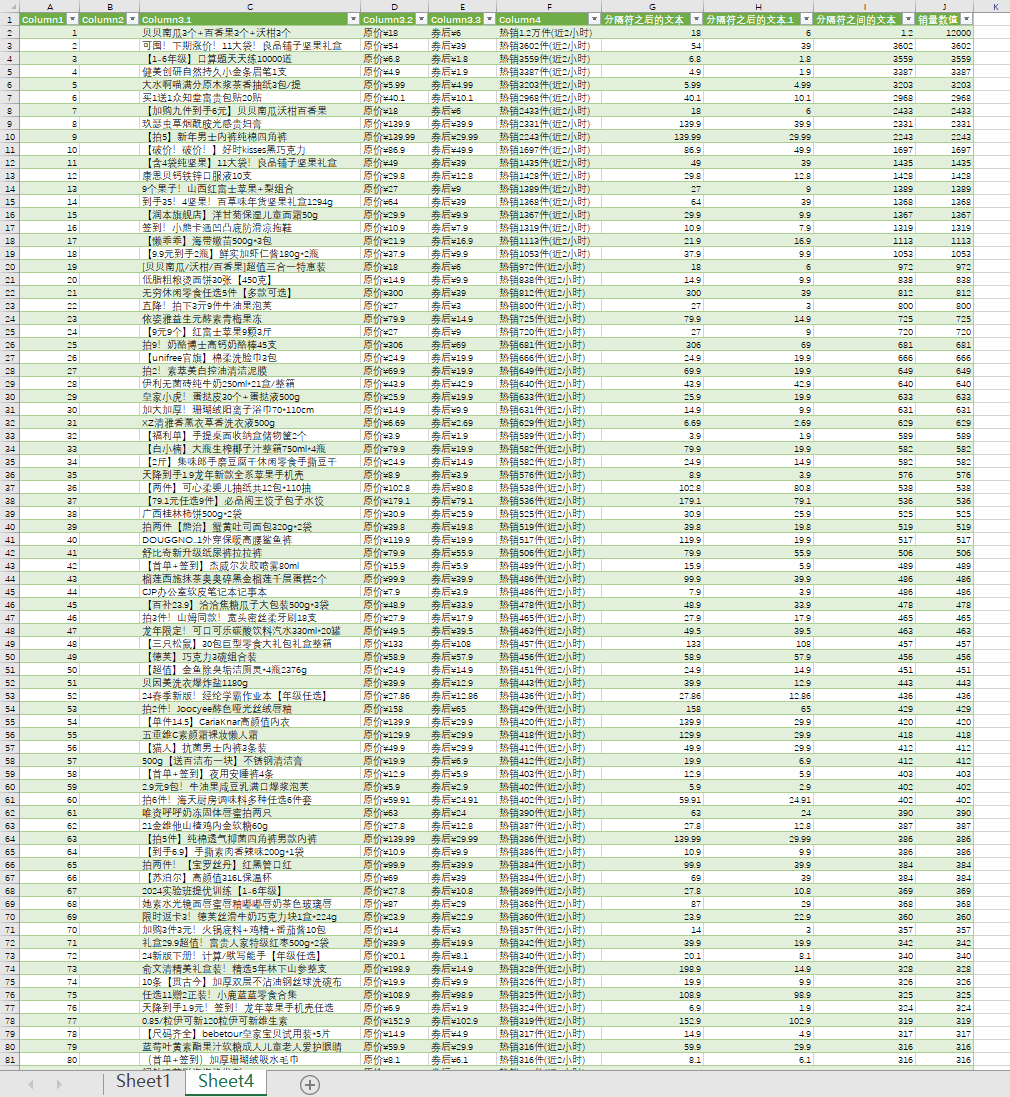
- 将PQ编辑器中的数据导出到excel表格中:主页——关闭并上载
2. excel实现分页爬取
需求:爬取经管之家的最新主题
url:https://bbs.pinggu.org/z_index.php?type=1&page=1
- 将url放置excel的自网页获得响应数据(与上面案例一样操作),然后将数据转换进去PQ编辑器
- 点击视图——高级编辑器——将第一次爬取的代码修改为分页爬取代码
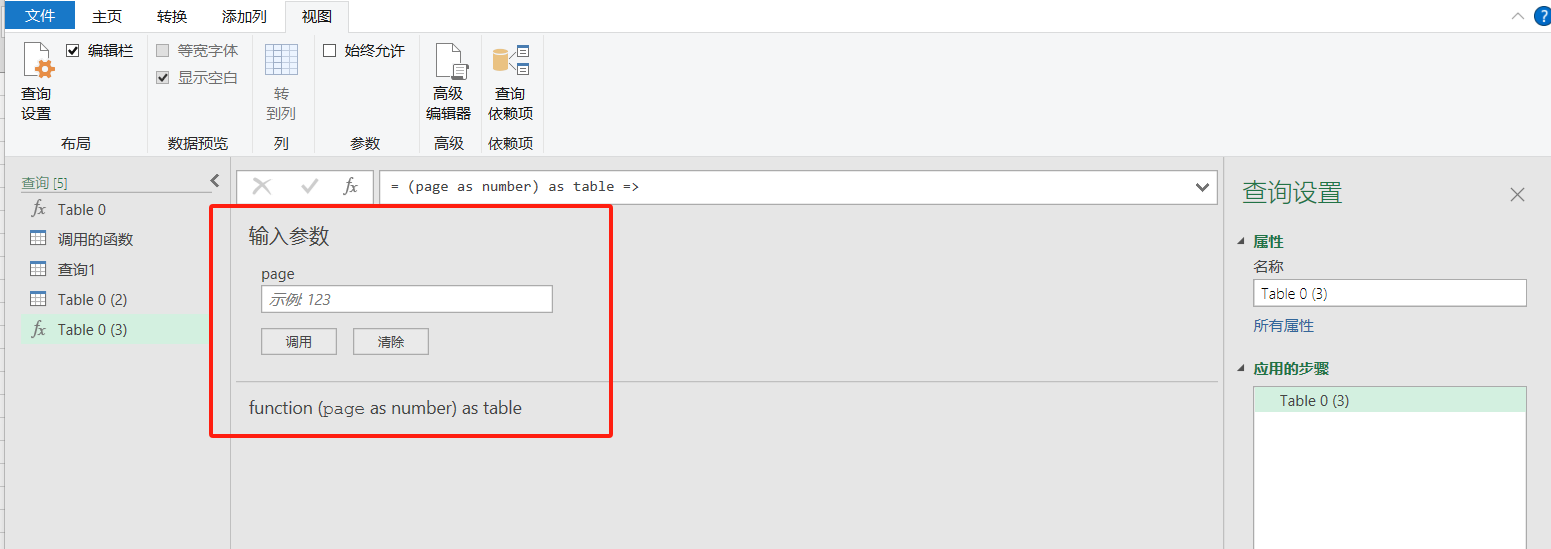
(page as number) as table =>
let
源 = Web.Page(Web.Contents("https://bbs.pinggu.org/z_index.php?type=1&page="&Number.ToText(page))),
Data0 = 源{0}[Data],
更改的类型 = Table.TransformColumnTypes(Data0,{{"", type text}, {"主题", type text}, {"版块", type text}, {"回复/查看", type text}, {"最后发帖", type text}})
in
更改的类型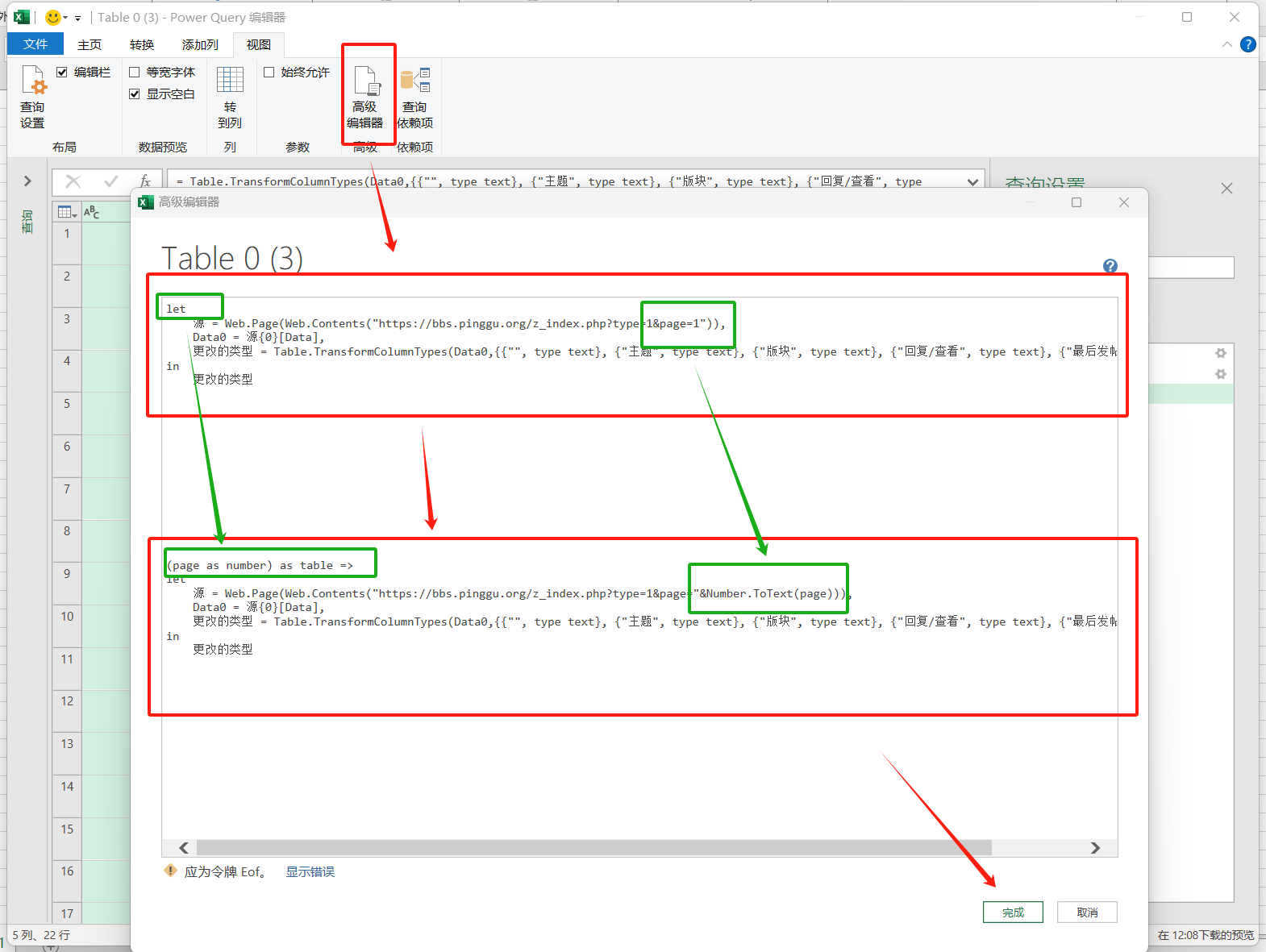
然后得到一个需要输入参数的函数页面,此时输入对应页面页数参数(比如说:3,表示第三页)仅仅只可以爬取输入参数页面的数据
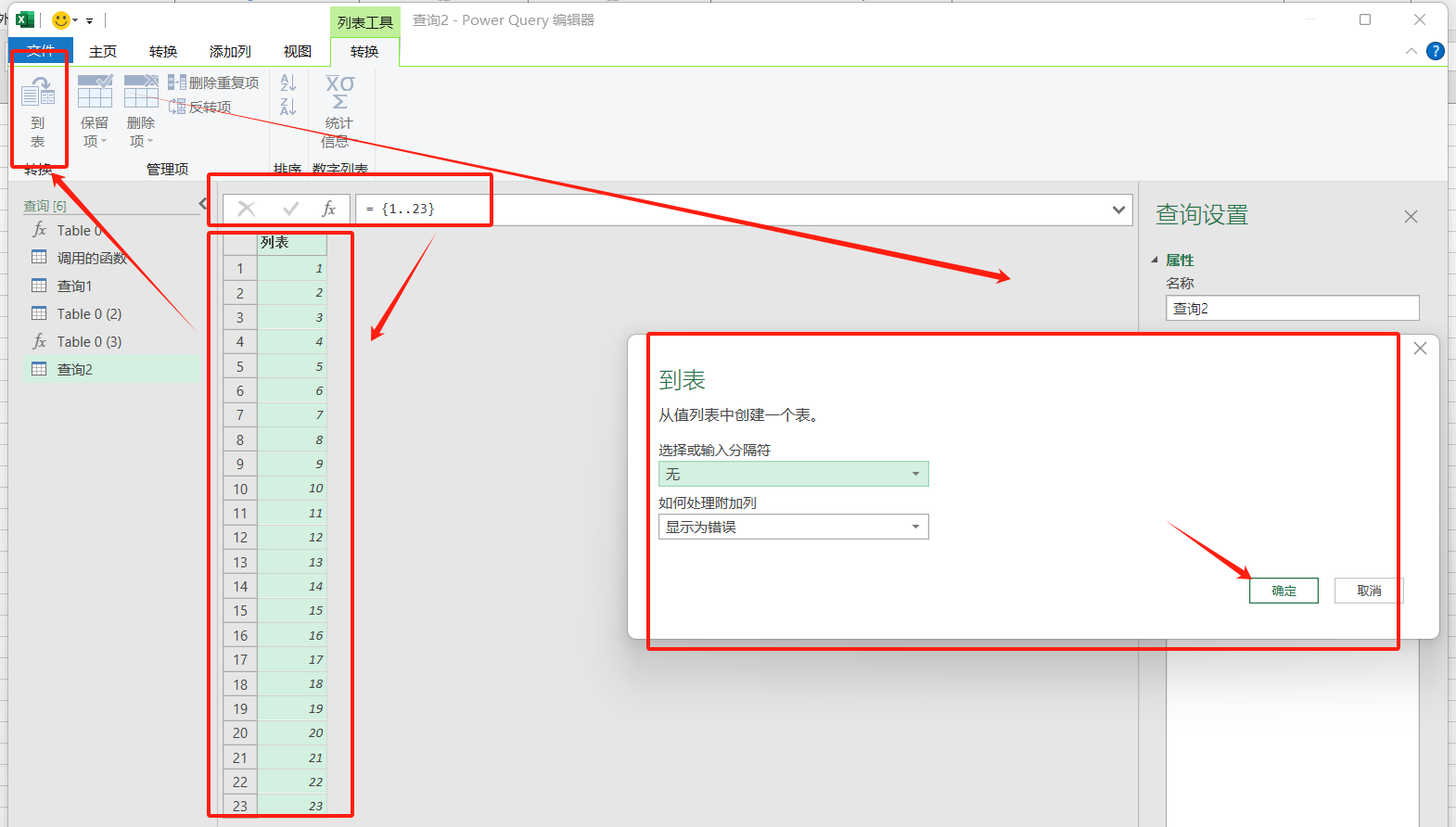
- 通过构建一个列表来获得全部页数页面的数据:主页——新建源——其他源——空查询——输入
={1..23},23是当前url下可以爬取到的最大页面页数——到表——确定
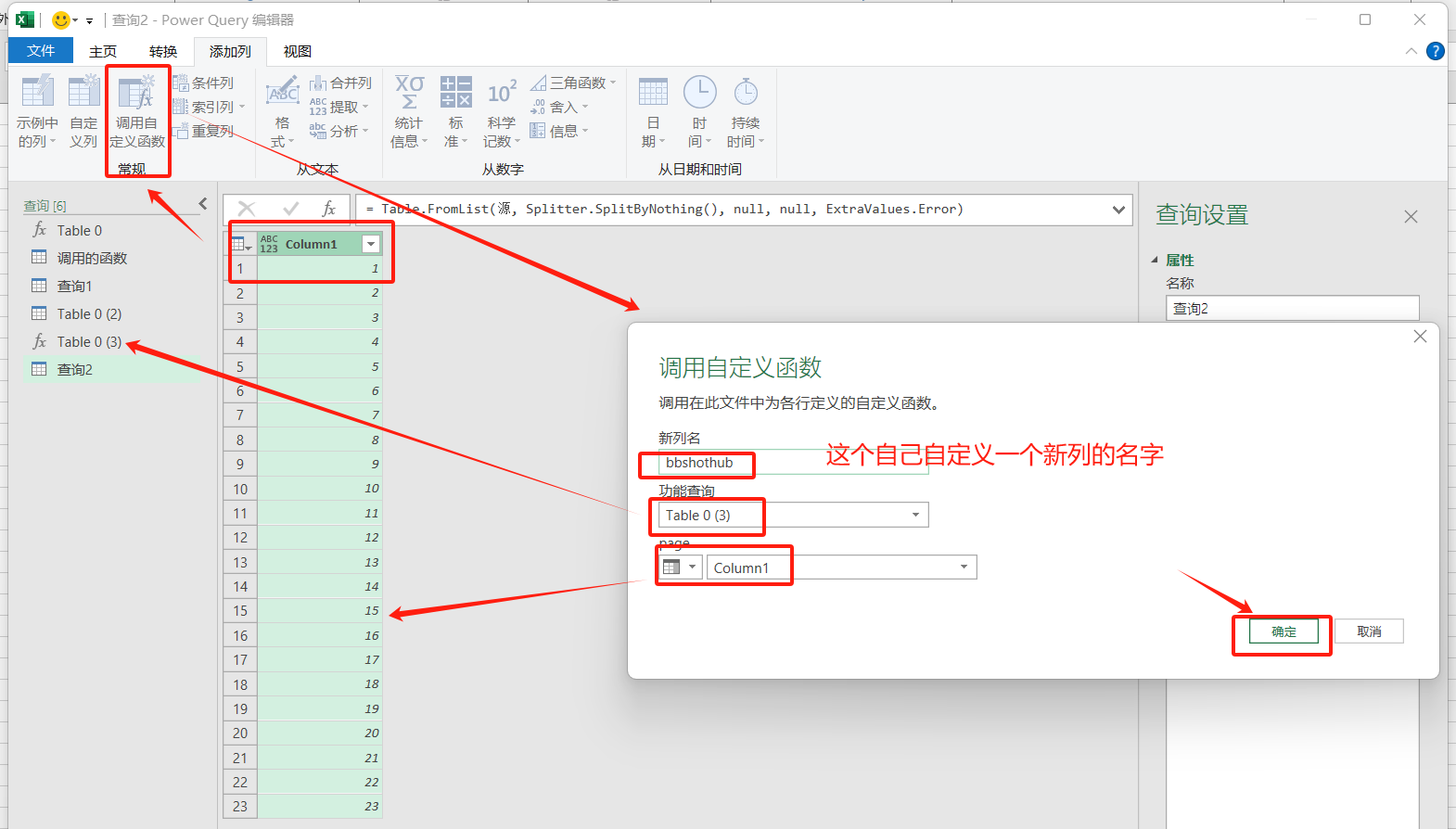
- 将bbs所有页面的数据都导出到上一步生成的23个列表中:添加列——调用自定义函数——确定。功能查询选的是此前高级编辑器代码生成的函数table列
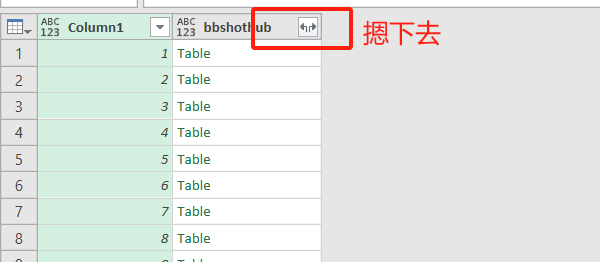
- 得到数据,并关闭PQ编辑器返回上载数据至excel表格