基尼系数作业笔记
计算基尼系数作业笔记
1. 基尼系数计算方法
基尼系数(Gini index、Gini Coefficient):是国际上通用的衡量居民内部收入分配差异状况的重要分析指标
本文基尼系数的数据来源于国家统计局网站公布的年度省份经济指标,选取2000-2021年的国内生产总值和年末总人口作为基尼系数计算的数据来源。
基尼系数有很多种计算方法,比较常见的有(1)和(2)两种方法,分别为直接算法和定积分算法,但是二者的本质都是一样。计算我们国家基尼系数的方法步骤可以根据公式的顺序来做:
- 将人口分为
个等分组,即每组人口占总体的比重相等,本次作业是把分组设置为全国 31 个省份,即是 ; - 我们假定一定数量的人口按收入 gdp 由低到高的顺序进行排列,可以理解为 gdp 越高的地方人口也越多,然后按照 gdp 排序的顺序来计算人口的累计权重,最后肯定是广东累计为 1,因为广东的 gdp 是最高的;
- 计算:
是 从第 组到第 组人口累计收入占全部人口总收入的比值; - 计算:
是从第 组到第 组累计人口与总人口占比; - 最后按照公式利用 stata 程序来计算基尼系数
则基尼系数为:
经济含义是:在全部居民收入中用于不平均分配的百分比。基尼系数最小等于
2. 数据来源
这次作业的基尼系数数据都是来源于国家统计局公布的数据,根据吴三忙和李善同(中国地区差距的历史考察与演变新趋势)的做法,本次对基尼系数的计算也是采用各省国内生产总值作为收入的代理变量,而人口数量则是以每年的年末总人口作为变量。由于国家统计局网站上只有2000年以后的数据,虽然有 1998 年之前的来自《新中国 50 年统计资料汇编》和 1999~2008 年的来自 历年《中国统计年鉴》,但是以往的数据统计中可能存在偏差或者不准确,所以只使用 21 世纪以来的统计数据,保证了数据的可信度。
3. 计算结果呈现
stata结果输出:
| 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 |
|---|---|---|---|---|---|---|---|---|---|---|
| .4178749 | .4193591 | .4216978 | .4242178 | .4257422 | .4313496 | .4335349 | .4321351 | .4264635 | .4256171 | .421909 |
| 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
| .4138578 | .407726 | .4059537 | .4070725 | .4160148 | .4195554 | .4197291 | .4189523 | .4186618 | .4181757 | .4170442 |
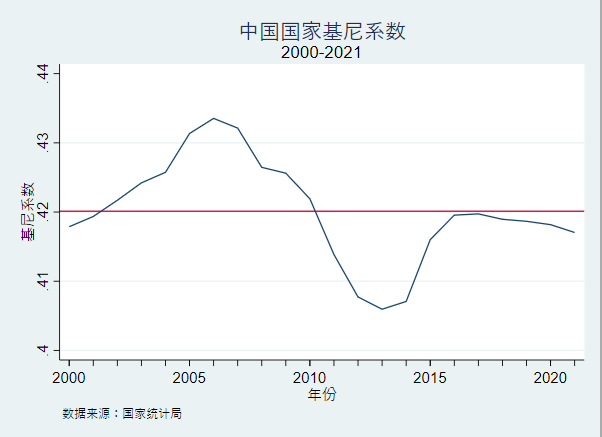
4. 结果说明
从stata输出的结果可以发现,从
2000~2021年,我们国家的基尼系数有一个先升高后下降再后上升再下降的过程,但是整体而言的基尼系数值都是超过了国家境界线
5. 代码
sysdir set PLUS ".\ado\plus"
sysdir set PERSONAL ".\ado\personal"
ssc install tidy //package下载
cd E:\Users\置上\Desktop\区域经济学
***=======数据处理========
import excel "E:\Users\置上\Desktop\区域经济学\年末总人口.xls", sheet("分省年度数据") firstrow
gather _2021年 _2020年 _2019年 _2018年 _2017年 _2016年 _2015年 _2014年 _2013年 _2012年 _2011年 _2010年 _2009年 _2008年 _2007年 _2006年 _2005年 _2004年 _2003年 _2002年 _2001年 _2000年
rename 地区 地区分组
rename variable 年份
rename value 总人口
save 人口面板数据.dta, replace
import excel "E:\Users\置上\Desktop\区域经济学\gdp.xls", sheet("分省年度数据") firstrow
gather _2021年 _2020年 _2019年 _2018年 _2017年 _2016年 _2015年 _2014年 _2013年 _2012年 _2011年 _2010年 _2009年 _2008年 _2007年 _2006年 _2005年 _2004年 _2003年 _2002年 _2001年 _2000年
rename 地区 地区分组
rename variable 年份
rename value gdp
destring 年份,replace ignore("_,年")
save gdp面板数据.dta, replace
use gdp面板数据.dta, clear
use 人口面板数据.dta, clear
merge 1:1 地区分组 年份 using 人口面板数据
drop _merge
save 人口—gdp面板数据.dta, replaces
***========计算基尼系数========
gsort 年份 gdp //先对年份进行排序,再按照某一年份内的省份gdp进行排序
bysort 年份: gen Rect = _n/_N //计算人口累计百分比
bysort 年份: gen Sgdp = sum(gdp) //计算逐年累计gdp
bysort 年份: egen Tgdp = sum(gdp) //计算这一年里面的全国总gdp
bysort 年份: gen Rect_gdp = Sgdp / Tgdp //计算按照gdp排序的逐个省份累计gdp百分比
bysort 年份: egen gini = sum(2*(Rect- Rect_gdp)/_N) //把上面计算的Wj和Pj套进公式进行计算
table 年份, statistic (mean gini) //绘制表格
save gini数据.dta, replace
duplicates drop gini, force //只留下每一年的全国基尼系数值用作画图
twoway (line gini 年份 ,ytitle(基尼系数) xtitle(年份)), note(数据来源:国家统计局) title(中国国家基尼系数) subtitle(2000-2021) xtick(2000(1)2021) yline(0.4201202) //画图
graph save "E:\Users\置上\Desktop\区域经济学\基尼系数图.gph", replace