调节效应
调节效应
1. 调节效应的定义
调节效应是指原因对结果的影响强度会因个体特征或环境条件而异,这种特征或条件被称作调节变量,交互项模型是对调节效应进行建模的主要方式。接着讨论不同处理变量的调节效应情形
- 当存在一个处理变量的情形。在大多数时候,一项因果推断研究只关注一个处理变量,仍记作 D, 将调节变量记作 M,则有:
若存在回归系数
如果
如果
除了报告系数的估计结果之外,通常还会根据需要报告因果效应的一个或几个估计值(以及标准误、置信区间、显著性检验的
p 值等)。例如,

根据公式推导上图调节效应关系,可知:
- 当调节效应是虚拟变量的情形。当调节变量 M 为虚拟变量时,还可以把交互项模型等价地理解为分组回归:
意味着当 M = 1 和 M = 0 着两种情况是讨论分组回归两个组之间的组间异质性,可以理解为我们平常在论文中看到的异质性检验的做法,例如:当 M = 1(男生)和 M = 0 (女生)时,D 对 Y 研究的时学习天赋和学习成绩之间的关系。
分组回归下 D 对 Y 的因果效应的组间异质性可以通过交互项模型来检验,即表现为交互项 M × D 系数估计的统计显著性。这种检验总是有必要的,因为组间异质性不能诉诸于直观判断。例如,D 对 Y 的因果效应在 M = 0 组是不显著的,在 M = 1 组是显著的,但它们之间的差异很可能是不显著的。就是说:在M=0\1 的调节作用下的分组回归,我们除了要讨论组内的 D 对 Y 的显著性,也要讨论组间的差异是否是显著的,此时就表现为对交互项 M × D 系数估计的统计显著性探究。
为了和调节效应的基本模型相适应,可以对(2)进行转换,此时
第一种是报告(1)式的结果,这种方式的好处是直接显示了 D 对 Y 的因果效应的组间异质性(看交互项系数),缺陷是 M = 1 组的因果效应没有直接显示;
第二种是分组报告(4)式的结果,这种方式的好处是直接显示了这两个组的因果效应,缺陷是因果效应的组间异质性检验还需要额外通过(1)式的交互项来实现;
第三种是报告(5)式的结果,这种方式的好处也是直接显示了这两个组的因果效应,因果效应的组间差异虽然没有直接显示,但是可以通过检验
来实现,也可以通过(1)式的交互项来实现。
- 处理变量和调节变量二者均为虚拟变量的情形
当处理变量 D 和调节变量 M
均为虚拟变量时,交互项系数有一种方便的理解:处理组(D = 1)与控制组(D =
0)的结果均值的组间差异之差异,简称双重差分(Difference in
Differences)。对于(1)式的转换形式:
特别地,当 D 为处理实施后的虚拟变量,M 为是否最终接受处理的虚拟变量,这种特殊的调节效应模型就是双重差分模型。反过来说,无论 D 和 M 是离散变量还是连续变量,无论其变动性是截面维度还是时间维度,交互项系数都应该在双重差分的意义(组间异质性)下去理解。
如何在双重差分的意义下表述交互项系数的经济含义?
| D | M | Y | 经济含义 |
|---|---|---|---|
| 是否上大学 (虚拟变量) |
是否是男生 (虚拟变量) |
工资水平 | 男生和女生上大学的回报率的差异 |
| 是否上大学 (虚拟变量) |
家离大学有多远 (连续变量) |
工资水平 | 家距离大学的距离远近对上大学回报率的差异 |
| 一国金融发展水平的指标 (连续变量) |
某一行业外部融资依存度的指标 (连续变量) |
该国该行业增加值的增长率 | 一国不同外部融资依存度不同行业下,金融发展水平对该行业增长率的影响 |
| 数字化转型 (连续变量) |
是否是政策试行区 (虚拟变量) |
GDP | 是否是政策试行区的分组下,数字化转型对GDP增长的影响 |
- 调节效应分析和异质性分析的关系
调节效应分析和异质性分析这两者是一回事。最简单的理解:当调节变量 M 是虚拟变量时, 相当于把全样本分为 M = 0 和 M = 1 两个组,交互项 M × D 的系数就是分组进行的 Y 对 D 的回归中 D 的系数的组间异质性。当 M 是连续变量时,本质上并没有发生变化,D 对 Y 的因果效应受到 M 的调节,也就是可以理解为,D 对 Y 的因果效应在高 M 组和低 M 组之间存在异质性。而异质性分析更重要的作用正是通过分析因果关系 的作用机制来强化因果关系论证。
并且调节效应分析和平时我们论文看到的异质性分析(总样本回归和分样本回归)其实还是存在较大的区别的,调节效应和分组回归的区别:分组回归:放宽了假设,允许控制变量系数不一致;调节效应:做交互项时,控制变量系数一样。假设存在两个分组为
D = 0 和 D = 1:
2. 调节效应变量中心化处理
有时会对调节变量进行中心化(去均值)处理,中心化的意义还在于改善对结果的理解。中心化后,
变量的原点移到了样本均值的位置,将(8)式改造成如下等价形式:
3. 调节效应分析论证因果关系
如果从统计上发现了 D 与 Y 的相关性,并且想要主张 D 是 Y 的原因,那么可以通过检验 D 影响 Y 的某个具体机制来对从 D 到 Y 的因果关系进行论证。论证的逻辑如下:
- 提出一个 D 影响 Y 的理论 T。根据这个理论 T ,D 通过某个机制影响 Y,并且可以识别出这一机制在某些子总体中存在, 在另一些子总体中不存在,令 M = 1 表示存在这一机制的影响下 D 对 Y 效应,M = 0 表示不存在这一机制下的 D 对 Y 的影响效应;
- 在 M = 1 组,发现 D 与 Y 的相关性继续存在,而在 M = 0 组,D 与 Y 的相关性不复存在;
- 可能导致 D 与 Y 出现相关性的竞争性解释还包括 Y 影响 D 的反向因果理论 R,或者有混淆因素同时影响 D 和 Y 的遗漏变量理论 C。如果无法想象理论 R 或理论 C 发挥作用的机制在 M = 1 和 M = 0 组存在差异,则理论 R 或理论 C 很可能不成立。否则,应该在 M = 0 组也观察到 D 与 Y 的相关性。
这样就完成了因果关系的强论证。这一逻辑的总结见表 1。但是其实用最大白话说着来理解就是:研究 D 与 Y 的相关性时,首先我们先从 D 通过某个机制 T 影响 Y ,也就是最纯粹的研究从 D 到 Y 的因果关系,但是也许会存在反向因果理论 R 或者是遗漏变量理论 C 的存在导致了有 D 与 Y 这样的相关性关系,但是这个时候我们通过引入两组不一样的样本进行回归(M = 1 和 M = 0)。
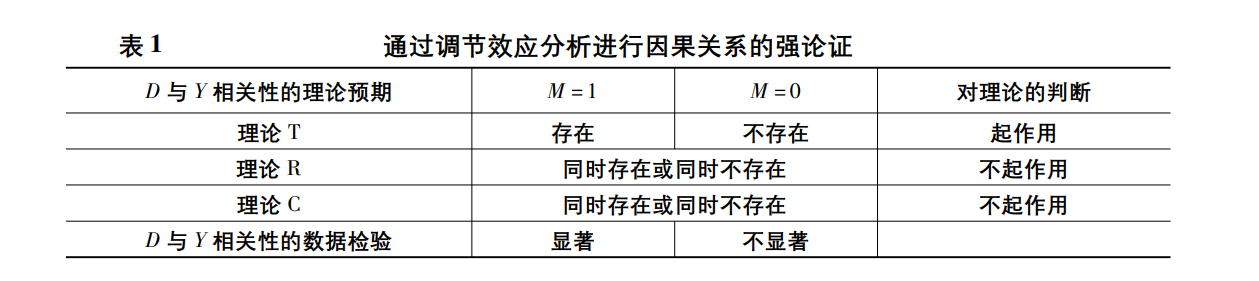
有时两组中 D 与 Y 的相关性都存在,但在 M = 1 组这种相关性更强,表现在 Y 对 D 的回归中 D 的系数估计绝对值在 M = 1 组更大,且组间差异在统计上显著。这时至少可以说,D 与 Y 的相关性不全是理论 R 或理论 C 所带来的,否则这种相关性应该在 M = 1 和 M = 0 这两组的组间差异是显著无差异的。这样尽管没有证伪理论 R 或理论 C,但至少证实了理论 T,也在因果论证上迈出了一大步。这一弱论证的逻辑可以通过对表 1 稍作修改来总结,如表 2 所示。
其实上述讨论了两种情况,第一种是当调节变量 M 是一个二元的虚拟变量的时候,我们怎么通过对两组(M = 1 和 M = 0)的组间异质性分析来得出 D 对 Y 的因果关系的论证,以及当调节变量是一个连续的情况。而当我们使用这个调节变量的时候就已经默认了其实调节效应,接着在这个成立了的调节效应下,我们去讨论 D 对 Y 的因果关系,如果调节效应下的分组的 D 对 Y 的因果关系是相同的,即是在 M = 0 组也观察到与在 M = 1 组的 D 与 Y 的相关性一致的结果,那么就是证明了机制 T (我们认为可能存在的 D 对 Y 的因果关系)其实是不成立的。但是我们一般在实证当中都是要求某种机制对某对分组之间产生组间差异,而其他机制无法在该分组组间产生相同的差异,就证明了在该分组的调节效应对于 D 对 Y 的关系产生作用。
举个例子:Brown(2011)试图验证竞争是一种重要的激励机制。但考核相对绩效的锦标赛机制要想发挥作用,得有一个前提——竞争者的能力必须相对均衡,当存在能力超强的“超级明星” 时,锦标赛机制反而可能出现负面效果。采用 1999—2006 年高尔夫球赛事中选手们的成绩数据, 发现在“超级明星”——“老虎”伍兹参加的赛事中,其他选手的表现比在伍兹缺席的赛事中选手们的表现要更差。这意味着,与伍兹同场竞技时,其他选手受到了负向激励(因为夺冠无望而不正常发挥)。由于伍兹参赛并不是一个随机事件,伍兹是否参赛与其他选手表现之间的负相关性存在竞争性解释:有可能因为伍兹参加的都是难度较高的赛事,而在高难度赛事中其他选手发挥相对较差是很自然的事,与激励无关。为了排除这种竞争性假说,进一步考察了伍兹参赛与否所带来的成绩反差在高水平选手还是低水平选手中体现得更明显。赛事难度的解释将预期到低水平选手的反差更大(低水平选手更难以适应高难度赛事),负向激励的解释将预期到高水平选手的反差更大(高水平选手更难以接受伍兹剥夺了他们夺冠的机会)。结果发现,高水平选手的表现反差大于低水平选手,这就证明了“超级明星效应”(尽管无法完全排除赛事难度的影响)。
4. 调节变量的选择
好的调节变量本身应该比较稳定,或者其变动是外生的,不受处理变量 D 或结果变量 Y 的影响。
如果 D 影响 M,那么交互项 M × D 可能捕捉的是 D2 的效应,也就是说,M 对 D 与 Y 关系的“调节”实际上反映的可能是 D 对 Y 的非线性影响。
朱家祥和张文睿(2021)认为,交互项在起始模型里就该出现,交互项系数统计显著是研究调节效应的起点,而不是终点。他们给出的理由是:如果先估计不包含交互项的基准模型,然后再引入调节变量和交互项,若交互项系数显著,就意味着在估计基准模型时,调节变量和交互项被留在了扰动项中,因此基准模型的估计是不一致的。如果调节变量本身是高度内生的,那么这个问题确实存在。但如果调节变量是外生的,在基准回归中遗漏它及其与处理变量的交互项,就不会造成估计偏误。此时,基准回归中处理变量的系数估计应该接近于交互项模型中的平均观测个体的边际效应。
5. 第二种基本策略
调节效应模型可以说是在因果识别中的第二种基本策略分析方法,在因果推断研究中,研究者处理内生性的主要思路往往聚焦在寻找合适的控制变量和控制策略,即找到导致内生性的原因,然后正式地刻画、测量和控制它。调节效应分析则提供了另一种处理内生性的思路,即尝试挖掘因果模型的新的可验证含义——处理变量和结果变量之间更丰富的相关性,如果这种相关性是其他因果“故事”所不能解释的,那么即便此时内生性仍然存在,但至少证明研究者所感兴趣的因果关系是存在的,否则这种更丰富的相关性不会出现。
在超级明星效应的例子中,无法完全控制“赛事难度”这一导致处理变量“伍兹是否参赛”存在内生性的因素(尽管可以最大限度地控制赛事级别、场地质量、奖金总额等),作者转而去挖掘更丰富的相关性:伍兹是否参赛导致的比赛杆数差异对高水平选手而言是否更大?这个事实可以被超级明星效应所解释,但不能被伍兹参加的都是高难度赛事所解释,因果论证的目的就达到了。
调节效应分析是一种很重要的因果论证手段,但在使用这种手段之前,首先要发展出一个说得通的理论,即是我们事先提出一种 D 对 Y 的理论机制 T:如果金融促进增长这个“故事”成立,那么就应该看到不同行业的效应大小不同(因为对金融的需求不同);如果超级明星效应这个“故事”成立,那么就应该看到不同选手的效应大小不同(因为激励强度不同)。然后再构建相应的交互项模型去验证这个理论。这就是因果推断理论先行(Theory Driven)的含义。
6. 调节效应的操作建议
- 将因果关系的作用机制检验视为因果识别的重要手段,尽量正式地讨论其如何有助于强化对文章主题(从 D 到 Y 的因果关系)的论证;
- 在研究设计部分详细阐述调节变量与调节效应的理论依据,而不是等到报告实证结果时再附会解释;
- 直观地展示调节效应,讨论其数值大小在经济上的重要性;
- 如果以处理效应的异质性本身作为研究目的,明确说明这种异质性的经济意义—读者为什么要关心这种异质性;
- 提高统计规范性,对异质性进行正式的统计检验;
- 将对作用机制和作用渠道的讨论进行严格区分, 不宜安排在同一章节下,明确其不同的写作目的。
7. 调节效应的示例
webuse grunfeld,clear
gen interact = mvalue*kstock //生成交互项,kstock作为调节效应变量
reg invest mvalue kstock interact
/*
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 358.51
Model | 7917141.5 3 2639047.17 Prob > F = 0.0000
Residual | 1442802.42 196 7361.23684 R-squared = 0.8459
-------------+---------------------------------- Adj R-squared = 0.8435
Total | 9359943.92 199 47034.8941 Root MSE = 85.798
------------------------------------------------------------------------------
invest | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
mvalue | .0920428 .0064136 14.35 0.000 .0793943 .1046913
kstock | .0496103 .0361521 1.37 0.172 -.0216867 .1209073
interact | .0000594 9.11e-06 6.52 0.000 .0000414 .0000774
_cons | 3.540558 11.18174 0.32 0.752 -18.51141 25.59253
------------------------------------------------------------------------------*/*中心化处理
webuse grunfeld,clear
center mvalue kstock
gen interact = c_mvalue*c_kstock
reg invest mvalue kstock interact
/*
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 358.51
Model | 7917141.51 3 2639047.17 Prob > F = 0.0000
Residual | 1442802.4 196 7361.23675 R-squared = 0.8459
-------------+---------------------------------- Adj R-squared = 0.8435
Total | 9359943.92 199 47034.8941 Root MSE = 85.798
------------------------------------------------------------------------------
invest | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
mvalue | .1084364 .0054148 20.03 0.000 .0977576 .1191152
kstock | .1138551 .0292737 3.89 0.000 .0561233 .1715869
interact | .0000594 9.11e-06 6.52 0.000 .0000414 .0000774
_cons | -14.1921 9.687665 -1.46 0.145 -33.29754 4.913348
------------------------------------------------------------------------------*/8. 调节效应交互作用图绘制
- 在 Excel 中绘制出交互图
在 Courser 有一门关于数据分析的课程叫做:Understanding Your Data: Analytical Tools。这门课程中有讲到如何 excel 做出调节作用的图像,可直接点击下载作者已经制作好的excel 模板。
也可以看一下面的知乎和B站的教程:
- Stata中绘制交互图
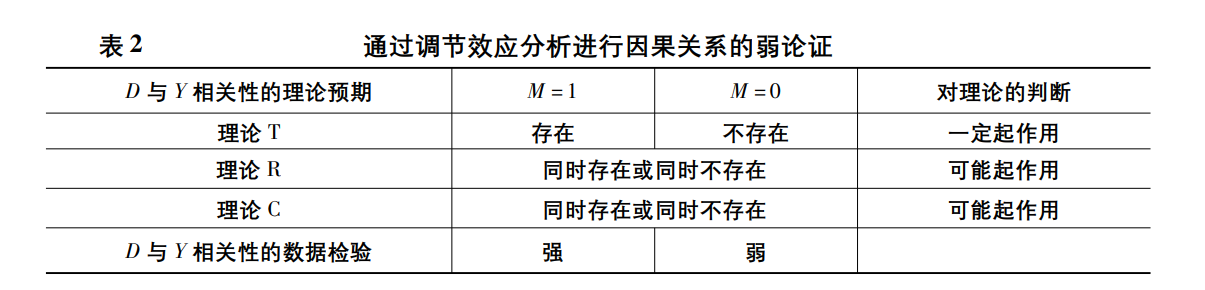
sysuse auto,clear
regress price c.length##c.mpg
est store regression
*分别求出自变量以及调节变量在均值上加减一个标准差的值
foreach v of var length mpg {
sum `v' if e(sample)
local low_`v'=r(mean)-r(sd)
local high_`v'=r(mean)+r(sd)
}
est restore regression //在调取保存的回归结果
*-y轴的范围从2000至10000,间隔为1000
margins , at(mpg=(`low_mpg' `high_mpg') length = (`low_length' `high_length')) //计算边际效应
marginsplot, xlabel(13 " " `low_mpg' "Low IV" `high_mpg' "High IV" 30 " ") ytitle("Dependent variable") ylabel(2000(1000)9000, angle(0) nogrid) legend(position(3) col(1) stack) title("") noci