Chapter4——STATA函数与运算符
Chapter4——STATA函数与运算符
0. 运算符exp
STATA 共有四种运算,分别是代数运算、字符运算、关系运算和逻辑运算。
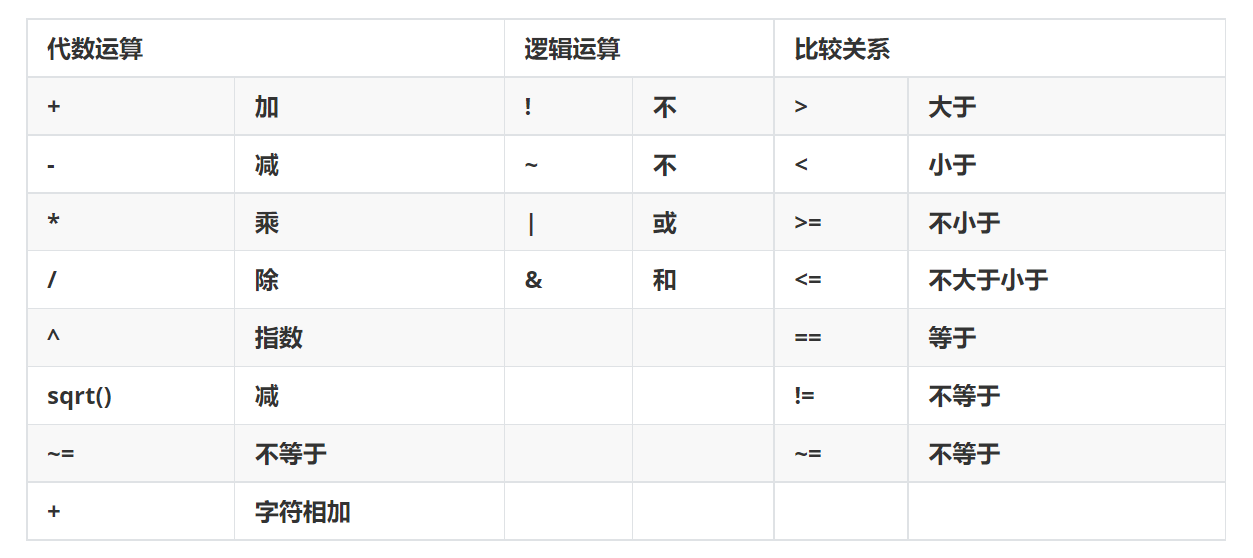
运算的优先序:{!(或),^,-(负号),/,*,-(减),+,!=(或=),>,<,<=,>=,==,&,| } ,当忘记或者无法确定优先序的时候,最好用括号将优先序表达出来,在最里层括号中的表示式将被优先执行。
- 代数运算
代数运算包括括加(+)、减(-)、乘(*)、除(/),幂(^)和负数(-),当遇到缺失值 或者运算不可行时(比如除数为零)均会得到缺失值。
di -(4+2^(4-2))/(2*4)
di -(2+3^(2-3))/sqrt(2*3)更多的情形是两个或多个变量的直接运算。比如,将进口车的价格都增加100元(可能是关税),而国产车不变。
sysuse auto,clear
gen nprice=price+foreign*100 //由于foreign的取值为0和1,所以只有1的进口车价格增加100元
list nprice price foreign- 字符运算
加(+)号同样可用于字符运算,当加号出现在两个字符之间时,两个字符 将被连成一个字符。比如把”我爱” “STATA”合并在一起。
scalar a="我爱"+"STATA"
scalar list a
scalar a=2+"3"[scalar]:Stata 命令的储存结果多存储在单值 Scalar 中
*知识点:单值scalar
*存放数值
scalar a=3
dis a
*存放字符串
scalar b="hello world"
dis b其实scalar和python中的赋值打印很想,只是stata中需要手动把值储存在scalar中:
a="i am dbsitu"
print(a)scalar a="i am dbsitu"
display a- 关系运算
关系运算包括大于、小于、等于;不等于、不小于、不大于等多种比较关系。 特别要注意到 STATA 中的等于符号为“==”,是两个等号连写在一起,不同于赋 值时用的单个等号“=”。
di 3<5 //输出结果为 1,意味着 3 小于 5 为真
di 3>5 //输出的结果为 0,意味着 3 大于 5 为假
di 3=5 //输出的结果为 0,意味着 3 不等于 4 当数据中含有缺失值的时候需要特别小心,因为系统缺失值大于任何一个数 据,利用这一点,我们可以使用条件语句排除缺失值。
- 案例:将年龄分组为 65 岁以下和 65 岁及以上两组,缺失值显然不能包括在任何 一组中。
clear
input age
38
.
65
42
18
80
gen agegrp1=(age>=65) //将大于65的数值赋值新变量的新值为1,包括缺失值
gen agegrp2=(age>=65) if age<. //将age大于65且排除缺失值的赋值为1
gen agegrp3=(age==65) if age<. //仅仅判断是否恰好为65岁
list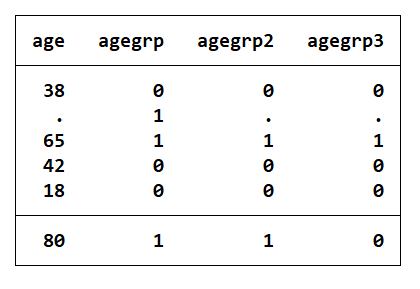
- 逻辑运算
逻辑运算包括非(!),和(&)、或(|)三种,主要用于条件语句中。
- 案例:列示出价格大于 10000 元的任何车,或者小于 4000 元的国产车。
sysuse auto,clear
list price foreign if price>10000|price<4000&foreign==0
list price foreign if price>10000|(price<4000&foreign==0)
list price foreign if (price>10000|price<4000)&foreign==01. 函数概览function
函数是一些STATA已经提前编写好的脚本小程序,这些小程序会对输入的数据按照一定的规则进行处理且报告结果。实际上由于STATA内嵌的函数较多,先学会查找函数help function,后逐渐掌握常用的函数命令,对于不熟练的函数,可以多加联系和查询加以巩固。
help function
/*
+--------------------------------------------------------+
| Type of function | See help |
|------------------------------+-------------------------|
| Date and time | datetime functions |
| | |
| Mathematical | mathematical functions |
| | |
| Matrix | matrix functions |
| | |
| Programming | programming functions |
| | |
| Random-number | random-number functions |
| | |
| Selecting time spans | time-series functions |
| | |
| Statistical | statistical functions |
| | |
| String | string functions |
| | |
| Trigonometric | trigonometric functions |
| | |
+--------------------------------------------------------+
STATA共包含八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。*/| 数值型函数 | 含义 | 举例 |
|---|---|---|
| abs(x) | 绝对值 | abs(-9)=9 |
| comb(n,k) | 从 n 中取 k 个的组合 | comb(10,2)=45 |
| exp(x) | 指数 | exp(0)=1 |
| fill( ) | 自动填充数据 | |
| int(x) | 取整 | int(5.6) = 5, int(-5.2) = -5 |
| ln(x) | 对数 | ln(1)=0 |
| log(x) | 以 10 为底的对数 | log10(1000)=3 |
| mod(x,y) | x - y*int(x/y) | mod(9,2)=1 |
| round(x) | 四舍五入 | round(5.6)=6 |
| sqrt(x) | 开方 | sqrt(16)=4 |
| sum(x) | 求和 | |
| 随机函数 | 含义 | 举例 |
| uniform( ) | 均匀分布随机数 | chapter10介绍 |
| invnormal(uniform( )) | 标准正态分布随机数 | chapter10介绍 |
| 字符函数 | 含义 | 举例 |
| real(s) | 字符型转化为数值型 | |
| string(n) | 数值型转化为字符型 | |
| substr(s,n1,n2) | 从 S 的第 n1 个字符开始, 截取 n2 个字符 | Substr(“this”,2,2)=is |
| word(s,n) | 返回 s 的第 n 个字符 | Work(“this”,3)=i |
| 系统变量 | 含义 | 举例 |
| _n | 当前观察值的序号 | |
| _N | 共有多少观察值 | |
| _pi | π为圆周率 | 3.14159 |
2.
数学函数math functions
- 三角函数,指数和对数函数
- 数学函数可以直接对数据进行运算,也可以对变量进行运算。对数据的操作:
di sqrt(4) //开方
di sqrt(6+3) //先相加在开方
di abd(-100) //求绝对值
di exp(1) //求e的一次幂
di ln(exp(2))
di _pi
di cos(_pi) //求cos(Π)- 数学函数可以直接对数据进行运算,也可以对变量进行运算。对变量的操作:
clear
set obs 5 //设定5个观察值
gen x=_n //生成新变量x,取值为1,2,3,4,5
gen y1=exp(x)
gen y2=ln(x)
gen y3=sin(exp(x))+cos(ln(x))
list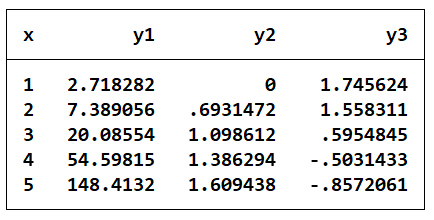
- 取整和四舍五入
- 取整
int()取整,不论后面的小数是什么,只取小数点前的数值
di int(3.49) //3
di int(3.51) //3
di int(-3.49) //-3
di int(-3.51) //-3- 四舍五入
round()取整,四舍五入,仅仅只看位数的后一位数是否大于等于4
di round(3.49) //3
di round(3.51) //4
di round(-3.49) //-3
di round(-3.51) //-4
di round(3.345,0.1) //四舍五入到十分位,3.3
di round(3.351,0.1) //3.4
di round(3.345,0.01) //3.35
di round(3.351,0.01) //四舍五入到百分位,3.35
di round(335.1,10) //四舍五入到十位,340- 对变量的操作
sysuse auto,clear
gen nprice1=price/10000
gen nprice2=round(nprice1,0.01)
list nprice* //比较nprice和nprice1的结果差别,看百分位位数- 求和及求均值
gen和egen
- 对比
gen和egen的区别
gen是用于修改和创造一个新的变量;egen只能使用专属的egen函数来为新变量计算变量值,并且需要在gen创造了一个变量的基础下创造新的变量。所以在使用gen命令时,_n和_N是我们常用的下标变量,用于表示行号和总观测值非常方便,但egen却无法使用。
egen是gen的扩展,平时生成变量用gen,如果想要使用某些特定的函数生成一些变量,就用egen。
clear
set obs 5
gen x=_n //生成新变量 x, x=1,2,3,4,5
gen y=sum(x) //求列累积和
egen z=sum(x) //求列总和,注意比较y和Z的不同
egen r=rsum(x y z) //求r=x+y+z总和
egen havg=rowmean(x y z) //求havg=(a+b+c)/3,计算有效均值,缺失值不进入平均运算
egen hsd=rowsd(x y z) //求x、y和z每一列的方差
egen rmin=rowmin(x y z) //求x y z这三个变量的最小值
egen rmax=rowmax(x y z) //求x y z这三个变量的最大值
list
egen avgx=mean(x) //求列均值
egen medx=median(x) //求列中值
egen stdx=std(x) //求变异系数 cvi=(xi-mx)/s,注意s=Σ(xi-mx)2
/(n-1)
replace y=3 in 3
egen byte dxy=diff(x y) //当x与y相等时,differ取0,若不相等为1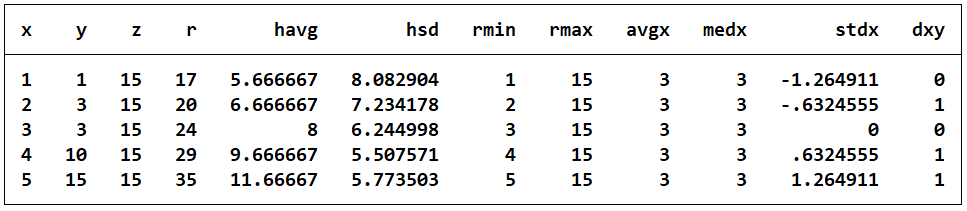
- 其他
- 案例1:
sysuse auto,clear
egen rmpg=rank(mpg) //求mpg的次序
sort rmpg
list mpg rmpg
egen highrep78=anyvalue(rep78),v(3/5) //若rep78不为3,4或5,则为缺失值
list rep78 highrep78- 案例2:交叉分组
clear
input a b
1 0
0 0
1 1
0 1
0 0
1 .
. 0
end
*按 a 和 b 来进行交叉分组,a=0,b=0 为第一组,a=0,b=1为第一组a=1,b=0为第一组,a=1,b=1为第四组,缺失值不参与分组
egen ab=group(a b)
egen ab2=group(a b),missing //将缺失的组当作另外的一组,增加了两组
list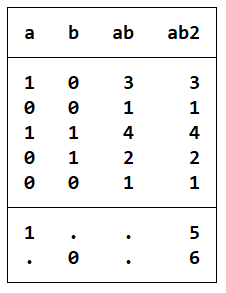
[group(x y)]:可以按照x和y的值进行交叉组合成不同的组合
- 案例3:按变量值范围分类
clear
set obs 10
gen age=_n
*生成新的分组变量agegrp,当年龄age在3及以下时(min/3)取值为1,3到6(3/6)为2,6以上(6/max)为3
recode age(min/3=1)(3/6=2)(6/max=3),gen(agegrp)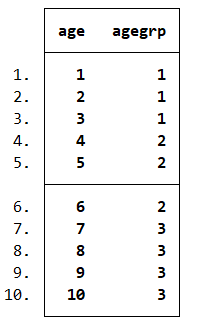
3.
字符函数string function
- 案例1:将美国汽车数据中汽车商标变量值简化为取前三个字母,得到一个新的变 量make3。
sysuse auto,clear
gen make 3=substr(make,1,3) //取变量make的前三个字符赋给make3
list make* //比较结果make和make3[substr(s,n1,n2)]:表示从字符串s的第n1个字节开始截取长度为n2的子字符串
use myclassmates,clear
gen lastname=substr(name,1,5)
list
- 案例2:下表的数据是一个多选题,请把这道多选题转化为四个单选题,例如变量 a 表示“你今天早餐吃的是:1 稀饭 2 馒头 3 大饼 4 豆腐脑”。变量 a 不容易处理,可以用以下命令转化为四个 0-1 变量,分别为 na1=是否吃稀饭,na2=是否吃馒头,na3=是否吃大饼,na4=是否吃豆腐脑。
clear
edit
/*a
2
2
2、1、3
1、2、4
4、2、1
1、2
2
1、2*/
gen na1=strops(a,"1")!=0
gen na2=strpos(a,"2")!=0
gen na3=strpos(a,"3")!=0
gen na4=strpos(a,"4")!=0
list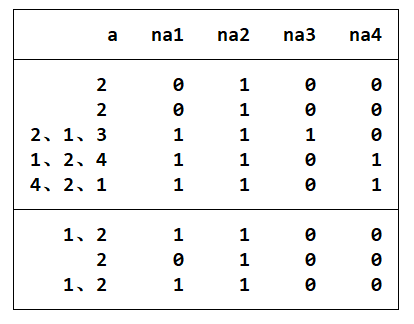
[strpos(s1,s2)]:在s1数据中如果可以找到s2,函数输出1;如果在s1数据中找不到s2,则输出0
- 案例3:
sysuse auto,clear
gen make2=word(make,2) //生成新的变量make2,取变量make的第二个单词,注意是单词不是字母,以空格为分隔
list make*
di word("this is a dog",4) //显示的是第四个字母dog[word(s,n)]:遍历字符串s的第n个单词
4. 分类操作by
clear
input x y
1 1.1
1 1.2
1 1.3
2 2.1
2 2.2
end
gen n=_n //生成一个新变量 n=1,2,3,4,5
gen N=_N //生成一个新变量 N=5,5,5,5,5
gen z=y[1] //生成一个新变量 z=y 的第一个观察值
by x,sort:gen n1=_n
by x,sort:gen N1=_N
by x,sort:gen z1=y[1]
list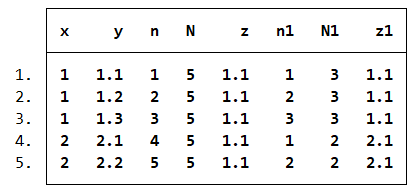
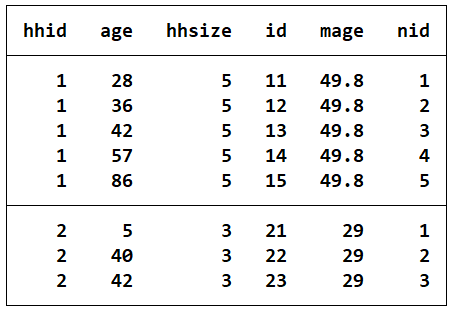
- 案例:下列数据为家庭成员数据 family.dta,其中 hhid 为家庭编码,age 为家 庭成员的年龄。要求:(1)生成一个新变量 hhsize,该变量表示共有多少个家庭成员。(2)给每个家庭成员一个编码 id。如第一个家庭的第一个成员编码为 11;(3)按家庭 生成一个全家成员平均年龄值mage。(4)对每个家庭,分别按年龄大小排序, 然后生成一个家庭成员代码,即家庭内年龄最小的成员代码为 1,年龄最大的家庭成员,代码为 nid。
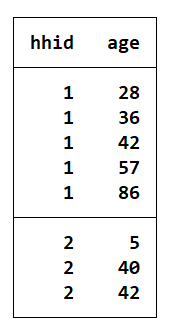
use family,clear
by hhid,sort:gen hhsize=_N //计算家庭的规模hhsize
by hhid,sort:gen id=_n+hidd*10 //位家庭成员编码
by hhid,sort:egen mage=mean(age) //求一个家庭的平均年龄
sort hhid age //按家庭户排序,在每一个户内按年龄排序
by hhid:gen nid=_n //在户内按年龄大小为家庭成员编码
list