Chapter2——STATA数据
Chapter2——STATA数据
0.
打开示例数据和网络数据use
当前路径下打开
use非当前路径下打开
sysuse
sysuse auto.dta,clear- 从网络获取数据
webuse
use http://www.stata-press.com/data/r9/nlswork
webuse nlswork,clear1. 数据类型
STATA通常会把变量划分为三类,分别是数值型,字符型和日期型
- 数值变量
| 存储类型 | 最小 | 最大 | 0-领域 | 字节 |
|---|---|---|---|---|
| byte | -127 | 100 | +/-1 | 1 |
| int | -32,767 | 32,740 | +/-1 | 2 |
| long | -2,147,483,647 | 2,147,483,620 | +/-1 | 4 |
| float | -1.70141173319*10^38 | 1.70141173319*10^36 | +/-10^-36 | 4 |
| double | -8.9884656743*10^307 | 8.9884656743*10^307 | +/-10^-323 | 8 |
当运算时对于运算结果的精度要求很高,需要将变量设置成浮点型或者是双精度型,另注意 1 和 1.0000 的精度是不同的,前者在 (0.5,1.5) 区间内近似,而后者在 (0.99995,1.00005) 区间内近似。若多次运算反复取四舍五入,精度较低时将使计算误差迅速变大,然而,精度高时占用的内存资源较多。
以下例子有助于理解变量存贮类型变换:
clear
*设置一个观察值单位,其实是生成了一个矩阵表格
set obs 1
*为这个观察单位中添加一个数值变量a
gen a=1
describe
*因为stata默认的存储类型是float,所以输出的是float
*compress在不损害信息的基础上压缩,使数据占用空间尽可能小,因为a数值<100,所以a储存最小是byte
compress
d //输出的是a经过compress压缩后类型byte
replace a=101 //替换a的数值为101>100,最小存储内存为int
d
replace a=100 //替换a的数值为100=100,最小存储内存为byte
compress
d
replace a=32741 //替换a的数值为32741>327441,最小存储内容为long
gen double b=1 //生成一个数值为1的变量b,其存储内存为double
recast double a //对a的储存内存修改为double
d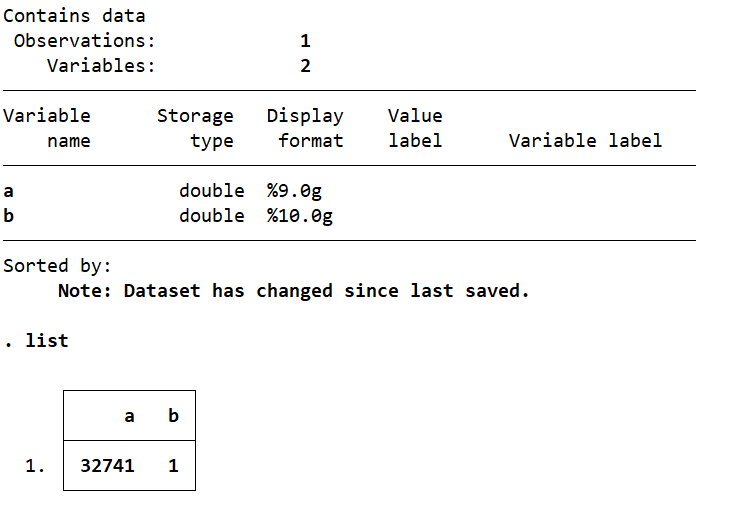
- 字符串变量
字符串变量由字母或一些特殊的符号组成(如地名〈籍贯〉变量,迁出地,住址,职业等等)。字符串变量也可以由数字来组成,但数字在这里仅代表一些符号而不再是数字。字符串变量通常以引号“”注标,而且引号一般不被视同为字符的一部分,注意这里的引号必须是英文输入状态下的引号。
字符串最多可以达 244 个字符。一般用
str#来表示字符的多少,如 str20表示将有 20
个字符。一般三个中文字的姓名需要 6 个字符,即是一个汉字占2个字符。
*在使用命令导入数据时,把字符型数据的字符规定为10个字符,一个汉字占2个字符
input id str10 name economy对于“125.27”这样的数值型的字符串,可以用real()函数或者
destring 命令转化成数值型变量。
- 日期型变量
在 STATA 中,1960 年 1 月 1 日被认为是第 0 天,因此 1959 年 12 月 31 日为第-1 天,2001 年 1 月 25 日为 15000 天。
- 缺失值
没有意义的计算结果显示为”.”。在另外一种情况中,当数据集中含有缺失值,STATA不是采用默认的“.”表示,而是采用空来表示,或者是-9996等来表示。如果要将其全部缺失值替换为“.”的命令是:
*将缺失值表示为-9996的转换为"."
mvdecode age,mv(1996)
*将缺失值表示为"."的转换成-9996
mvencode age,mv(9996)2. 数据类型的转换
- 将字符型数字转换成数值型数据
destring
*将destring网络数据集中的全字符数据,转换程数值型数据进行运算和储存
webuse destring1,clear //利用webuse导入的string数据
describe
sum
gen nincome=income+10
//描述所有变量的储存类型,发现都是string;因为所有的变量都是字符型的,所以sum出来的结果都是0,并且由于字符型变量无法进行四则运算,所以gen出来会报错type mismatch
destring,replace //可以将上述的字符型数据转化成数值型数据
sum
gen nincom=income*1.3
list nincom income- 对字符型数据进行数值型转换时,由于字符型数据存在各种的类型,比如说是date数据之间会存在空格(" "),price数据会有单位("$"),percent数据会有符号("%")。但是我们在对其进行数值型数据转换前需要把这些非数值性的符号去除
*当数据中的某个变量中有空格、符号等被识别为字符型数据时,需要剔除后destring转换成数值型数据
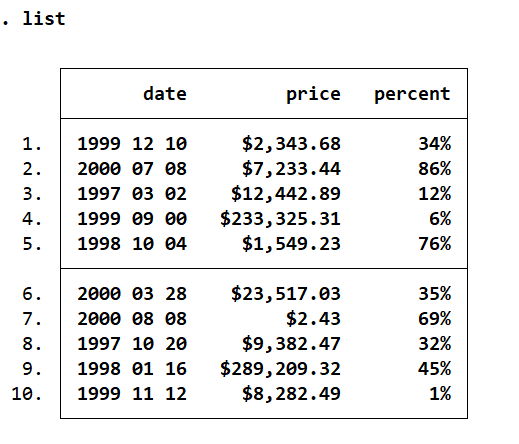
webuse destring2,clear
describe
list date
//尝试用destring对存在空格的字符型变量date进行数值型转换,但是会失败,因为没有剔除字符间的空格
destring dete,replace //提示:date: contains nonnumeric characters; no replace
destring date,replace ignore(" ") //提示:date: character space removed; replaced as long
des
list date
destring price percent,gen(price2 percent2) igonre("$,%")
list //此时price前的$和percent后面的%不见了
d //此时新生成的price2和percent2军编成数值型变量double和byte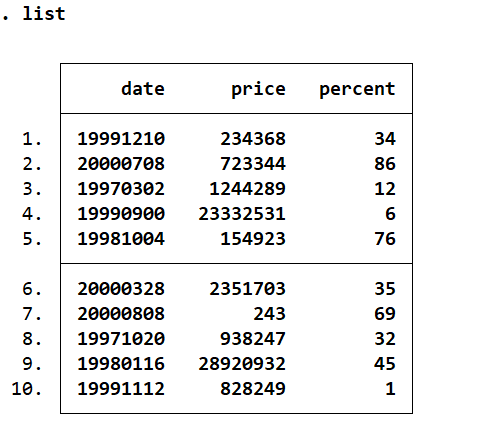
*其实可以一句代码把全部都改好
webuse destring2,clear
list
d
destring date price percent,replace ignore(" ,$,%")
list
d- 将数值型转换为字符型
tostring
*该数据中年月日的数据类型不一样,不能直接相加生成一个反映日期的新变量
webuse tostring,clear
d //发现month是字符型,而day和year是数值型
list
gen date1=month+"/"+day+"/"+year
//报错:type mismatch,由于 month 为字符型,年和日为数值型,不同类型不能相加
tostring day year, replace //将year和day转化成字符型变量
d //month,day,year三个变量都是字符型变量
gen date1=month+"/"+day+"/"+year //month,day,year三个字符型变量相加
list
*STATA可以通过mdy命令计算某一天距离1960年1月1日为第0天,计算从那天起直到括号中指定的某天date1一共过了多少天
gen date2=date(date1,"MDY")
list
di date("2001/09/30","YMD") //计算出生日记距离今天日期一共过了多少天3. 数据显示格式format
format只控制数据的显示格式(display
format),并不改变内存中数据的大小。以下以美国人口普查数据为例:
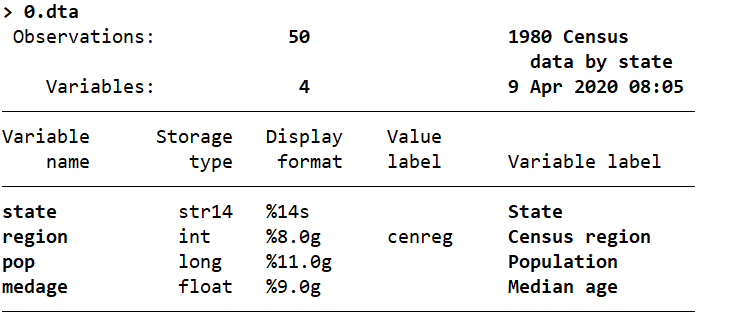
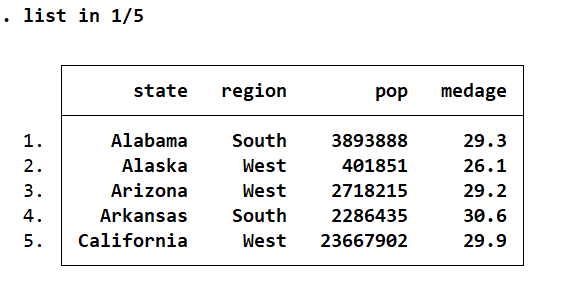
webuse census10,clear
d
list in 1/4
//发现此时state的变量的format为%14s,表示右对齐,共 14 个字符,%为固定用法
format state %-14s //14s前面加了一个负号修改state变量的显示格式由右对齐变为左对齐
list in 1/4
format region %-8.0g //region变量是数值型变量,在8.0g前添加负号修改其显示格式由右对齐变为左对齐
list in 1/4
format pop %11.0gc //pop变量的显示格式为%11.0g,在后面加上c,则每三位数间用逗号分开,c意为comma
list in 1/5 //发现第五个观察值没有任何变化(隔三位加逗号)
format pop %12.0gc //把把pop显示总长度数增加到12位
list in 5
format medage %8.1f //要求全部的medage都显示一位小数
list in 1/4
gen id=_n //生成一个新的变量id,取值依次为1,2,3
replace id=9842 in 3 //把id的第三个变量的id值更换为9842
list in 1/3
format id %05.0f //对于id值,使得前面用零把位数对齐
list in 1/3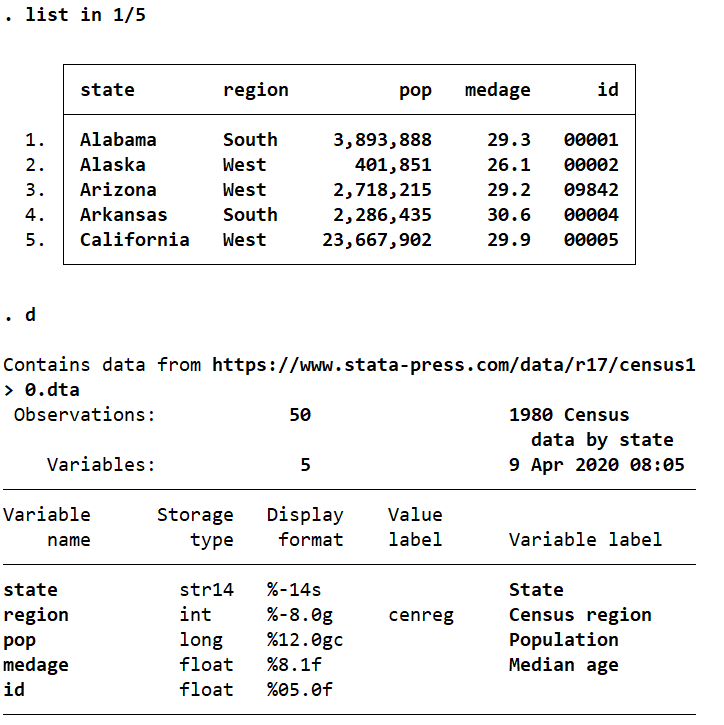
4.
在STATA中直接录入数据input
- 菜单式操作,打开数据编辑器,然后把数据复制黏贴
- 命令操作
| id | name | economy |
|---|---|---|
| 1 | John | 40 |
| 2 | Chris | 80 |
| 3 | Jack | 90 |
| 4 | Huang | 43 |
| 5 | Tom | 70 |
clear
input id str10 name economy //输入变量名,注意姓名前的str10
1 John 40
2 Chris 80 //录入第二个学生的学号和成绩
3 Jack 90
4 Huang 70
5 Tom 53
end
save economy5.
导入其他数据格式insheet
当我们有其他格式的数据,需要导入到 STATA 中进行分析,建议大家此时将其他格式数据复制到分析数据的文件目录下,然后直接用 STATA 的导入数据文件命令导入原始数据,用程序模式进行处理,然后导出处理结果。这样做的最大好处是:既不会破坏最原始的数据文件,又使我们的每一 步数据处理和分析过程都有迹可循。
打开csv或者txt格式的数据时,可以使用insheet命令实现导入,当数据中某个变量的位数特别长或者对导入数据的精度要求很高的时候,需要在该命令后面加
double 选项。
insheet using 3origin.csv, clear
insheet using 3origin.txt, clear
insheet using 3origin.txt, double clear6. 标签数据label
- 要掌握的命令:为了创建一个完整的文件,要掌握下面的命令。
| 命令 | 命令解释 | 用法示例 |
|---|---|---|
| pwd | 显示当前路径 | pwd |
| dir | 列示当前路径文件夹中的所有文件 | dir |
| mkdir | 在当前路径下创建一个新的文件夹 | mkdir d:/mydata |
| cd | 将 cd 后面的路径设定为当前路径 | cd d:/mydata |
| describe | 显示整个数据集的信息 | des |
| rename | 将现有变量名改为新的变量名 | rename gender sex |
| label | 给数据/变量/变量值加注标签说明 | |
| label data | 标签数据 | label data “2004 级成绩表” |
| label var | 标签变量 | label var name “姓名” |
| label value label define |
标签变量值 | label values gender genderlb label define genderlb 1 "男" 0 "女" |
| note | 为数据加注额外说明 | note: 9 月 10 日为数据加注说明 |
| list | 列示内存中的数据 | list id name |
| save | 保存数据 | save mydata, replace |
| erase | 删除数据文件 | erase mydata1.dta,replace |
- 要完成的任务:创建一个文件(文件名为 mydata.dta)并将其放D:/mydata
文件夹下(如果没有该文件夹,请用 mkdir 命令创建)。标签该数据(用 label
命令)使得任何一个使用该数据的人都能明白该数据(包括整个数据/其中的变量及变量值)的含义。原始数据的内容如下:
3origin.xls
clear
*如果想在d盘创建一个新的文件夹mydata来存放数据文件,加上capture后,STATA会自动判断,如果mydata文件夹已存在,则跳过该命令;若不存在则创建一个命名为mydata的新文件夹
capture mkdir d:/mydata
cd d:/mydata
*1. 导入3origin.xls的数据并保存在mydata
save 3origin, replace
use 3origin,clear
d
renpfix var v //renpfix可以将所有var开头的变量名修改为v开头(v+num)
rename v1 id
rename v2 name //将第二个变量v2重新命名为name
rename v3 gender
rename v4 minority
rename v5 economy
rename v6 math
d
*2. 标签文件
label data "2022年经济学学习成绩单"
note: 2022-09-28由Devin创建
note
*3. 标签变量
label var id “学号”
label var name “姓名”
label var gender “性别 1=男 2=女”
label var minority “民族”
*4. 保存和删除数据文件
compress //在保存文件前,在不损失任何信息的前提下压缩数据使占用空间最小
save mydata //保存数据,数据文件名为mydata。若mydata已存在,STATA会报错,可以修改新文件名为mydata1或者直接replace覆盖原文件mydata
save mydata1
save mydata,replace
erase mydata1.dta //删除文件